Explorando el Mundo de
Linux
Sistemas Operativos 2 · ISSD · 2025
Documentación del proceso
Proceso de instalación y configuración de Ubuntu Server 24.04 LTS en un Droplet de DigitalOcean
0. Introducción
El siguiente documento detalla el proceso llevado a cabo por el grupo para hostear un proyecto en un servidor remoto, en el marco de la materia Sistemas Operativos 2. La experiencia consistió en configurar una máquina virtual en Digital Ocean, aprender a conectarse y administrarla de manera remota desde Windows mediante SSH, gestionar usuarios y permisos en un entorno Linux, y poner en producción una aplicación Node.js utilizando herramientas como PM2, Nginx y Certbot.
El objetivo no fue solo lograr que la aplicación funcionara, sino entender cada paso del proceso: qué hace cada herramienta, por qué es necesaria y cómo se relaciona con las demás. Por eso, a lo largo del documento, cada comando está acompañado de su explicación.
Vale aclarar que lo documentado aquí refleja el camino correcto al que llegamos tras varias horas de trabajo y correcciones, no el orden exacto en que ocurrió todo. Los errores no se detallan para no extender innecesariamente el documento, aunque sí se mencionan algunos casos puntuales donde la solución encontrada es especialmente relevante para entender el resultado final.
1. Creación del Droplet en Digital Ocean
Una vez dentro de nuestra cuenta de Digital Ocean, en la sección Create Droplet, seleccionamos en la región del Datacenter, uno localizado en Estados Unidos (punto intermedio para todos los integrantes del grupo). El SO elegido fue Linux con distribución Ubuntu 24.04 LTS.
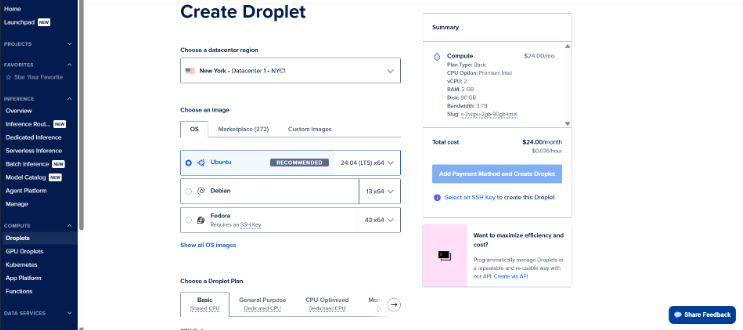
Seleccionamos la "máquina que vamos a alquilar" (plan que detalla CPU, RAM, Disco, ancho de banda).
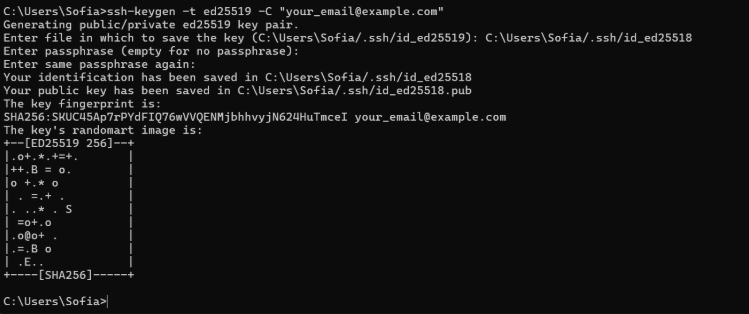
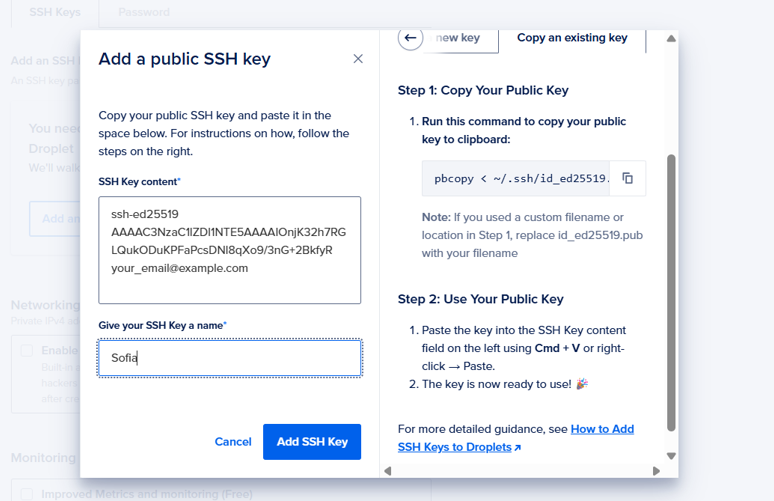
Acto seguido, cada integrante creó una llave SSH que cargamos para poder tener acceso (por motivos de seguridad este paso fue recreado con datos falsos y luego la llave fue eliminada).
Por último, le dimos nombre a nuestro Droplet.
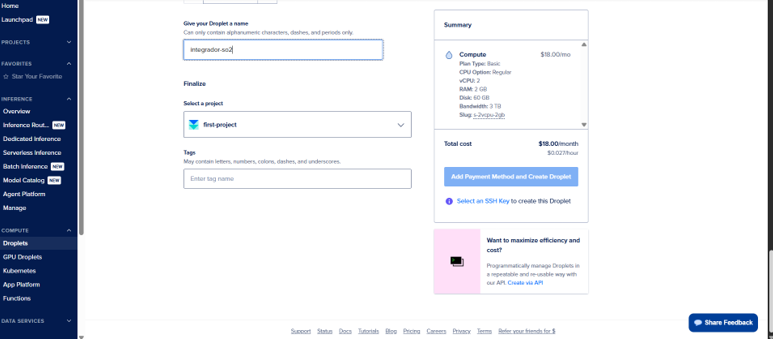
Así queda una vez funcional.
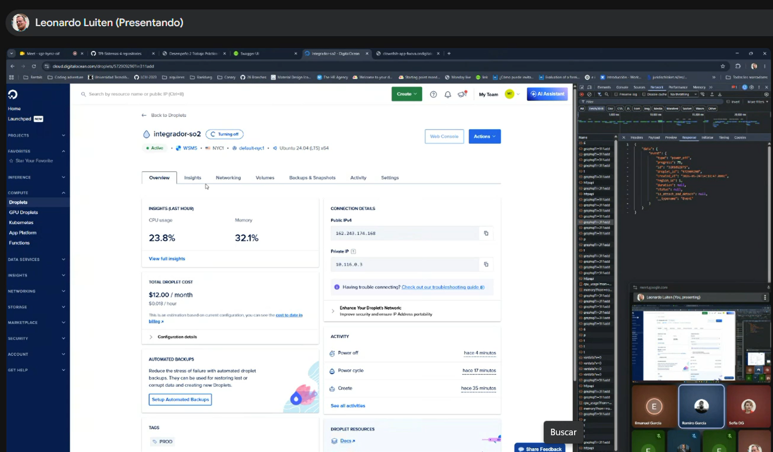
2. Conexión por SSH
En el buscador de VS Code ponemos >Remote-SSH (extensión previamente descargada) → Configurar Host SSH... → C:\Users\Sofia\.ssh\config y ponemos los datos del host (primeramente, configuramos todos los usuarios como root para comprobar la conexión sin problemas, luego los cambiaremos y otorgaremos los permisos pertinentes a cada usuario).
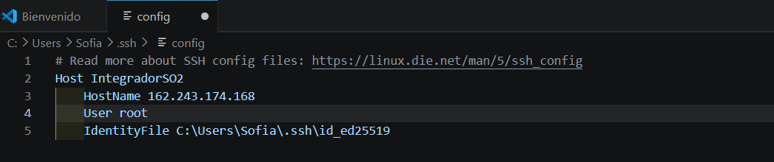
Una vez guardado, en el buscador de VS Code ponemos >Remote-SSH → Conectar al Host... → IntegradorSO2. Saldrá un aviso de que la conexión se está estableciendo, y finalmente se conectará. Podemos comprobarlo en la esquina inferior izquierda de la ventana de VS Code:

A partir de este momento estamos navegando en un entorno Linux, usando la máquina virtual a través de VS Code. Podemos comprobarlo al ver la estructura de archivos del entorno Unix.
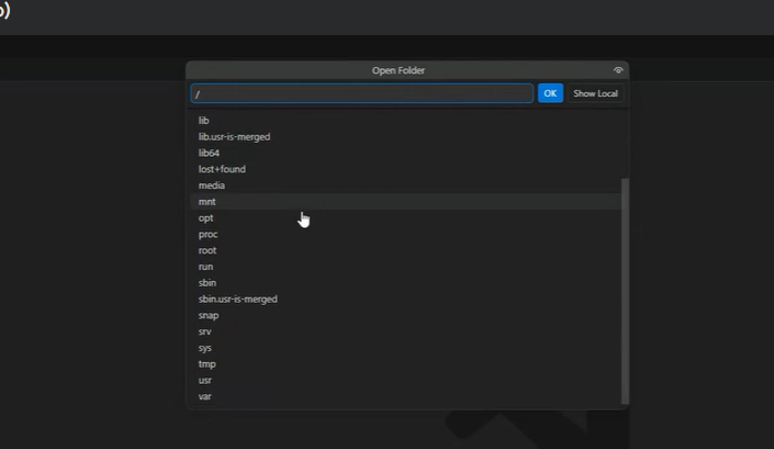
3. Creación de usuarios y asignación de grupos
Después de comprobar que todos pudimos establecer la conexión correctamente, procedemos a crear los usuarios. El usuario root agrega el comando: adduser "usuario" (en nuestro ejemplo: adduser rami)
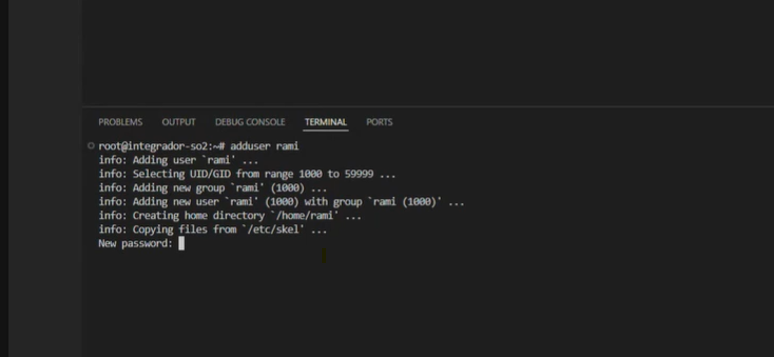
Automáticamente se le otorga número de id, se crea por defecto un grupo para el usuario, le crea un directorio "home", y le copia los archivos de etc/skel (carpeta de plantillas del sistema, para poder establecer su entorno base predefinido)
Luego continua pidiendo contraseña, nombre completo, y otros datos personales, que podrían servir, por ejemplo, para firmas o logs (por eso con los nombres de usuario decidimos utilizar camelCase y nombres sencillos). Por último pide corroborar os datos.
Con todos los usuarios generados, procedemos a la creación del grupo. Para ello, escribimos el comando groupadd "nombre del equipo" (en nuestro caso escribimos: groupadd equipo-trabajo) y agregamos a este los usuarios con el comando: usermod –aG equipo-trabajo rami ( podemos leerlo como: modificar usuario addgroup (agregar al grupo) nombre del grupo usuario)
Pasamos a otorgarle permisos al grupo:
Para cada usuario, en el directorio home/ se crea el directorio .ssh , y en él el fichero authorized_keys con el contenido de la llave de cada uno.
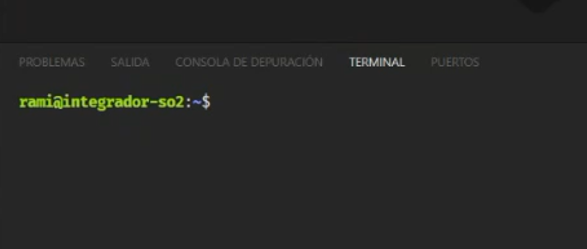
Con esto último hecho, ya podemos poner nuestros usuarios en la configuración, y entrar con estos. Nos damos cuenta porque en la terminal vemos el nombre del usuario y de la computadora:
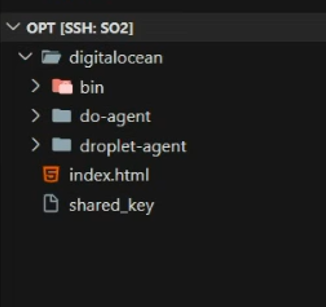
El directorio /opt sobre el que hemos otorgado los permisos será sobre el cual trabajaremos con el repositorio que es uno de los objetivos de este trabajo.
4. Conexión con GitHub y Descargas
Como tenemos nuestro repositorio privado, vamos a establecer una conexión entre Droplet y GitHub por medio de SSH. Para ello, crearemos una llave para nuestra "computadora" remota (esto sera para el root, lugo cada uno tendrá una particular repitiendo los pasos)
Para esto usamos el comando:
(se adjunta la imagen incompleta por temas de seguridad)
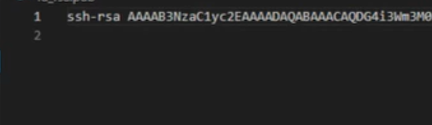
Luego hay que dar permisos al grupo:
Para asegurarnos de que utilice esa llave, vamos al /.ssh de la máquina virtual y creamos un fichero "config" con los datos de la llave que va a utilizar y donde lo hará (esto lo hacemos en cada usuario)
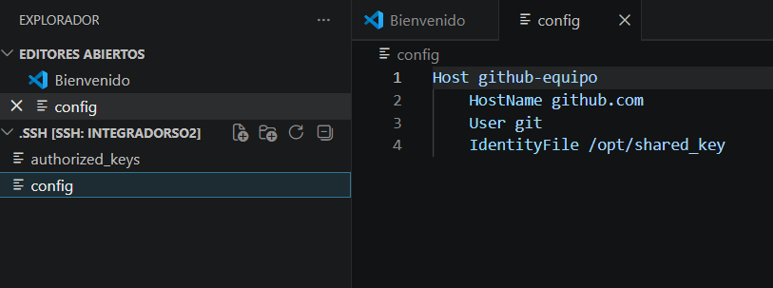
Con la llave creada, vamos a nuestro repositorio, Perfil => Settings => SSH and GPG Keys, y allí nombramos la llave y pegamos la llave pública generada
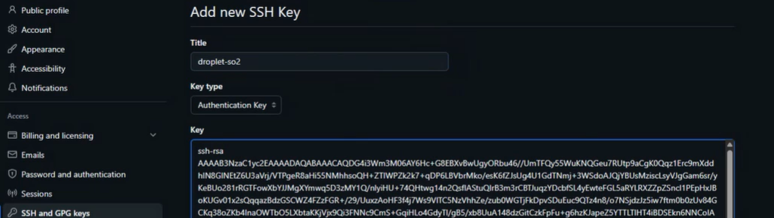
Por último, clonamos el repositorio entrando en la terminal el comando:
Si todo está bien, se descarga el repositorio. Esto es suficiente que lo haga un solo integrante del equipo, no es necesario repetirlo
Ahora tenemos que instalar las dependencias. Podemos o no verificar si ya están instaladas en el proyecto haciendo
En nuestro caso no estaba instalado, por lo que lo hicimos con
Verificamos la versión nuevamente
Y tenemos la 9.2.0. Ahora instalamos node mánager de la siguiente manera en la carpeta compartida del proyecto
Luego, abrimos nano:
/etc/profile.d/ es una carpeta especial de Linux donde los scripts que pongas se ejecutan automáticamente para todos los usuarios cuando abren una sesión.
En nano ponemos
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"
export PATH="/opt/nvm/versions/node/v22.22.3/bin:$PATH"
Así todos los usuarios del grupo tienen NVM disponible automáticamente al conectarse, sin tener que configurar nada en cada uno por separado.
Instalamos la versión de nvm que usamos en el proyecto
Y por ultimo, instalamos npm
Para terminar con la preparación de proyecto, copiamos las variables de entorno que estábamos usando en local (pegamos el archivo directamente en el explorador de archivos de VS Code para simplificar)
Para asegurarnos de que todo esté correcto hacemos una build
Y por último, ya podemos arrancar el servidor
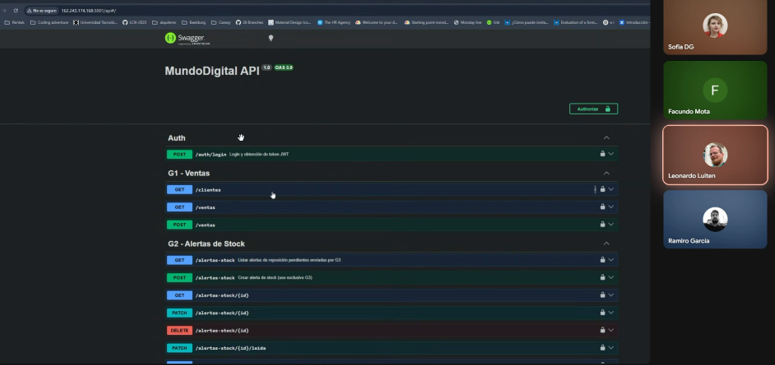
Y en el navegador probamos con
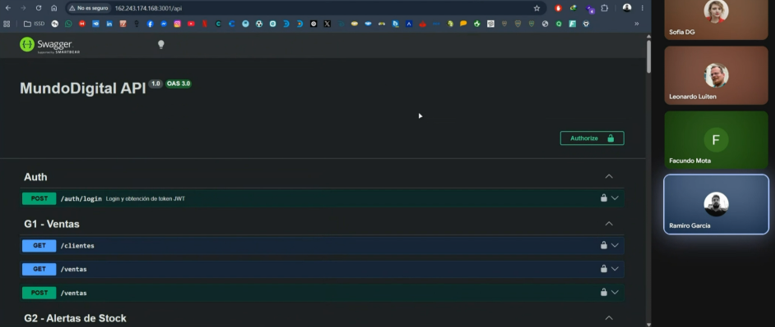
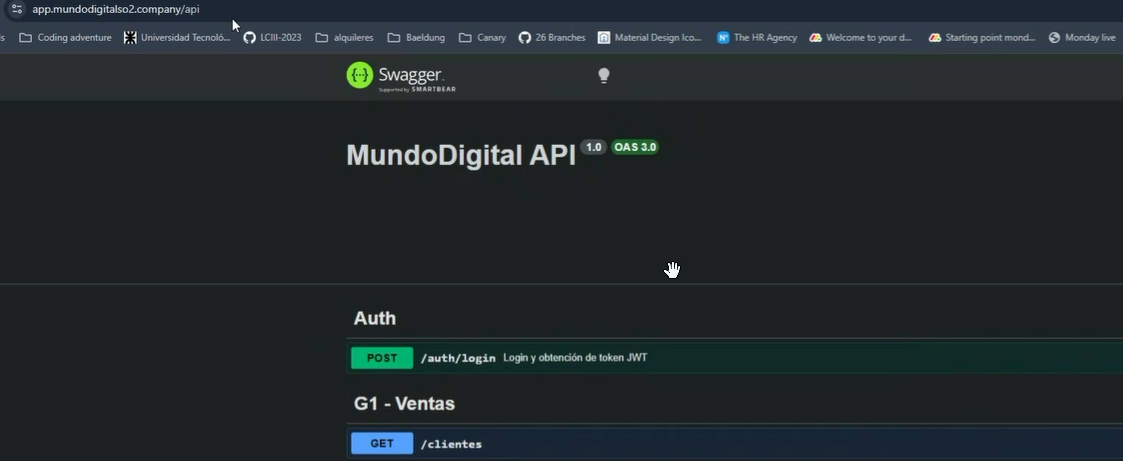
Y podemos ver el swagger al que anteriormente teníamos acceso cuando corríamos en local.
5. Implementación de PM2
Instalamos PM2 de manera global (toda la máquina virtual) haciendo:
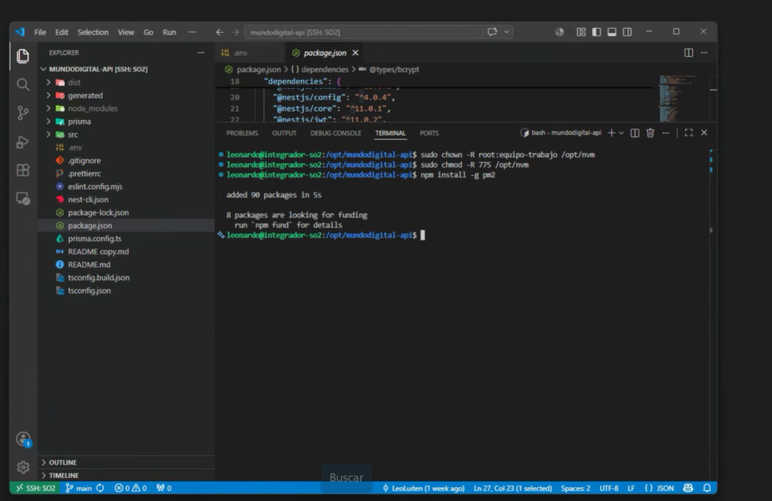
Para que todos los usuarios tengan acceso, creamos un directorio para pm2 en el directorio compartido
root@integrador-so2:~# sudo chown root:equipo-trabajo /opt/pm2
root@integrador-so2:~# chmod 775 /opt/pm2
Y en nano agregamos el path del home de pm2
export PM2_HOME=/opt/pm2
Y actuaizamos la autoreferenciaidad del archivo ("sourcear")
E iniciaizamos con
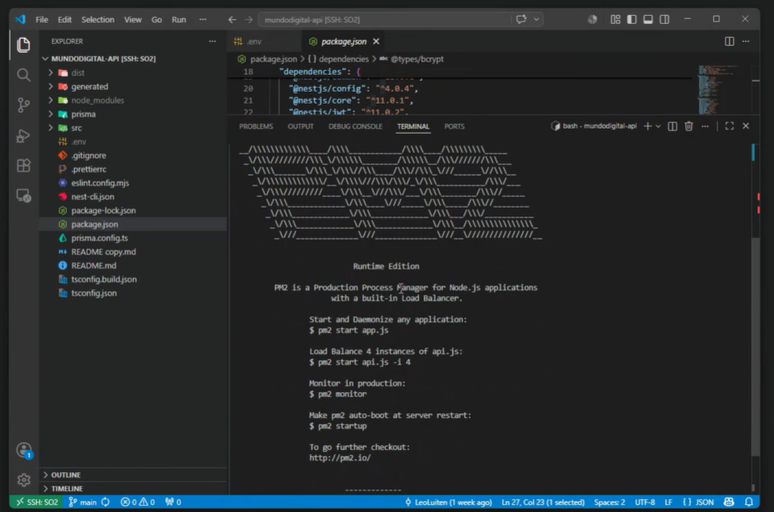
El propio pm2 genera un comando que modificamos, basándonos en la documentación oficial de PM2, para que se instale donde queríamos y no donde lo sugería, así funcione en una sola instalación para todos los usuarios:
Levantamos la app:
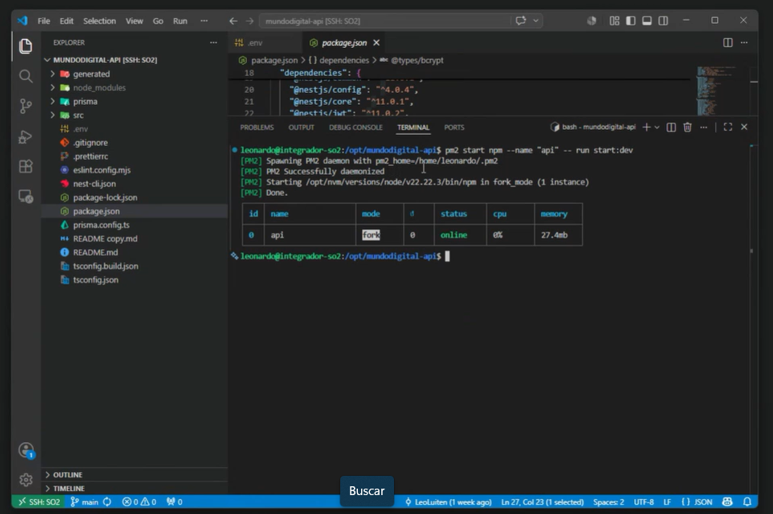
Si ponemos pm2 log api podemos ver el estado del servicio:
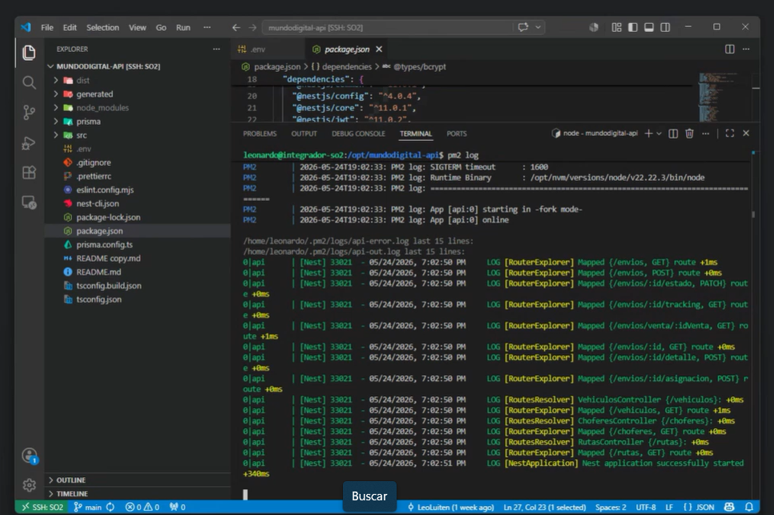
Y lo comprobamos:
Y guardamos con
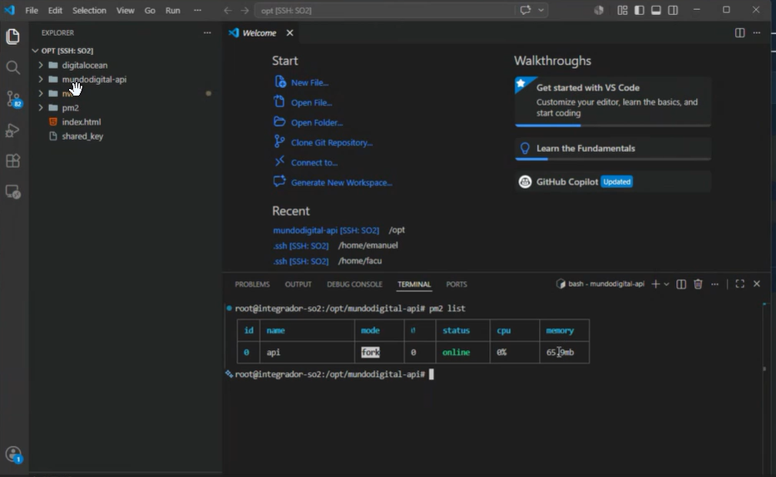
Ahora, aunque cerremos la consola, si hacemos pm2 list podemos ver el servicio que corre y no se detuvo
6. Implementación de Nginx
Antes de comenzar, es útil entender el concepto de proxy inverso que utilizaremos. Como explicó nuestro compañero: es como tener un buzón en un hotel. Es imposible tener una casilla para cada habitación, entonces en vez de eso hay un recepcionista que recibe. El cartero no necesita saber en qué habitación está Juan Pérez, sabe que está en ese hotel y tiene ese nombre, se lo deja al recepcionista y este es el que se lo entrega. En nuestro caso, Nginx es el recepcionista que recibe todos los pedidos HTTP y los deriva a la app Node corriendo internamente en el puerto 3001.
En primer lugar, actualizamos apt, que al ser local puede estar desactulizada:
Y luego instalamos Nginx :
Ahora configuramos el firewall con la herramienta de Ubuntu de configuración sencilla de firewall (ya que por defecto bloquea casi todo tráfico):
root@integrador-so2:~# sudo ufw enable
root@integrador-so2:~# sudo ufw app list
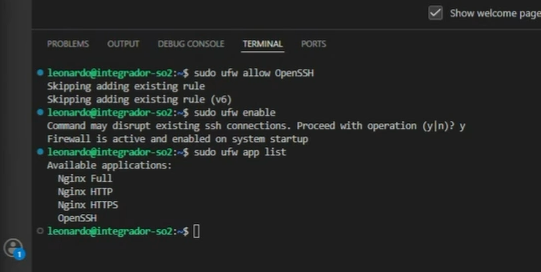
Hay tres perfiles de firewall que nos permite configurar Nginx, utilizaremos por ahora el más restrictivo:
Y verificamos los cambios realizados:
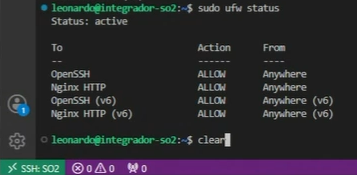
Al final de este proceso podemos verificar que el proceso está activo
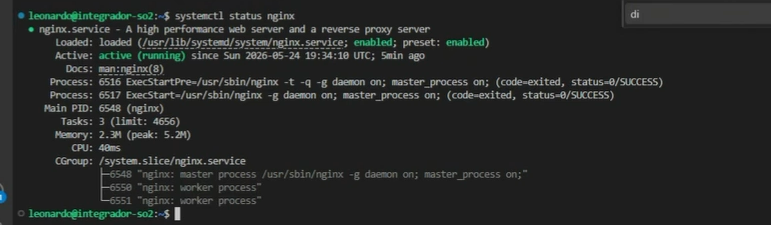
Ahora lo probamos en el navegador web ingresando la ip
Como todo software tienen su ciclo de vida que podemos controlar con
root@integrador-so2:~# sudo systemctl stop nginx
root@integrador-so2:~# sudo systemctl restart nginx
root@integrador-so2:~# sudo systemctl reload nginx
root@integrador-so2:~# sudo systemctl status nginx
Ahora configuraremos los server blocks (la configuración de servidor para cada dominio que tengamos, ya que se pueden tener varios en un mismo servidor)
Nota:
nosotros compramos un dominio de Vercel para este trabajo. Como anteriormente ya teníamos desplegado el trabajo en Vercel, tuvimos que utilizar un subdominio para que no interceptara el nuevo dominio.
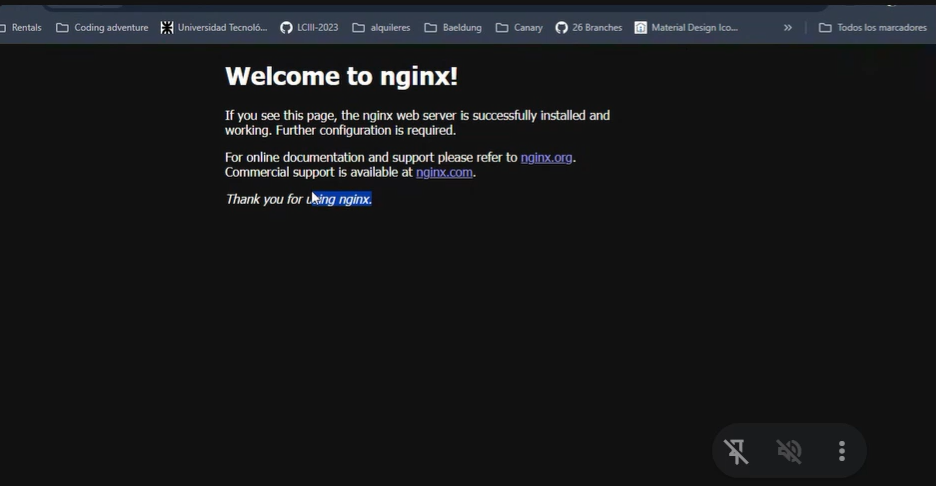
Esta bienvenida de Nginx que acabamos de ver es el server block que viene configurado por defecto para poder probar si está funcionando correctamente, aunque no tengamos una página propia aun que mostrar "de cara al publico"
Primero creamos un directorio para el dominio:
(en este caso www no es por world wide web sino que es una ubicación dentro del directorio de nuestra computadora virtual)
Luego, como siempre hacemos, cambiamos los permisos:
root@integrador-so2:~# sudo chmod -R 755 /var/www/app.mundodigitalso2.company
Y creamos una pagina simple en nano siguiendo la estructura que nos otorga la documentación (la cual luego fue cambiada para presentar esta página)
<head>
<title>Welcome to app.mundodigitalso2.company!</title>
</head>
<body>
<h1>Success! The app.mundodigitalso2.company server block is working!</h1>
</body>
</html>
Ahora creamos un directorio para nuestro sitio en el directorio sitios disponibles:
Se abre nano y ponemos la configuración sugerida por la documentación:
listen 80;
listen [::]:80;
root /var/www/app.mundodigitalso2.company/html;
index index.html index.htm index.nginx-debian.html;
server_name app.mundodigitalso2.company www.app.mundodigitalso2.company;
location / {
try_files $uri $uri/ =404;
}
}
Este archivo le dice a Nginx qué puertos escuchar, dónde están los archivos del sitio y cómo responder a los pedidos.
Activamos la configuración creando un enlace simbólico en la carpeta de sitios activos:
Un enlace simbólico es como un acceso directo de Windows: el archivo original sigue estando en sites-available, pero Nginx mira sites-enabled para saber qué sitios tiene que servir. Si algún día queremos desactivar un sitio, simplemente borramos el acceso directo sin tocar el archivo original.
Seguimos probando que todo esté funcional y que no haya errores, y reiniciamos Nginx:
root@integrador-so2:~# sudo systemctl restart nginx
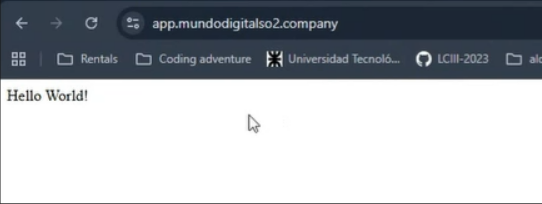
Finalmente, si en el navegador ponemos nuestro dominio aparece:
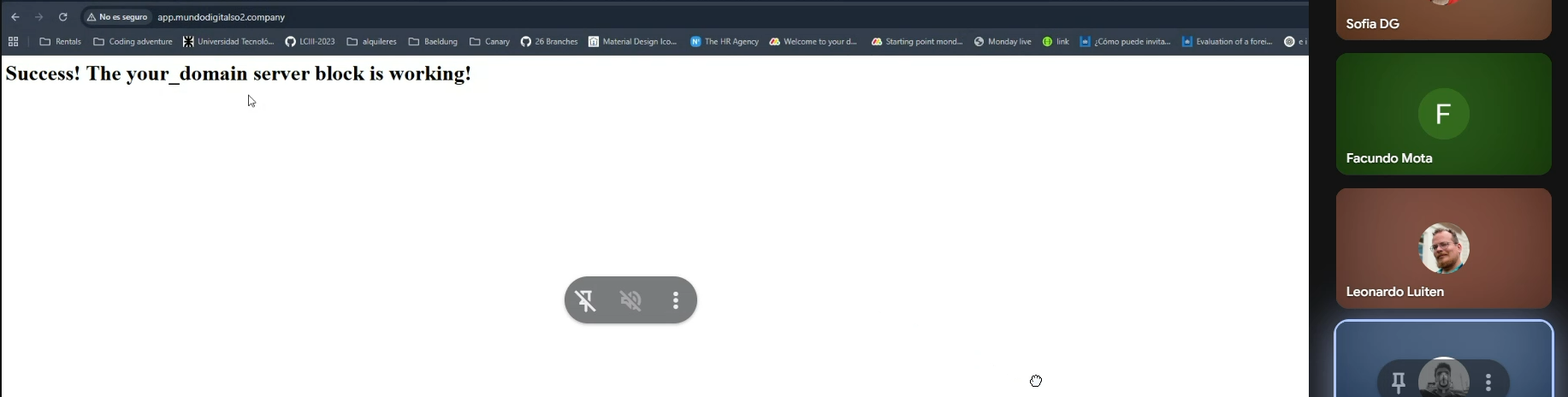
7. Configuración del certificado SSL con Certbot
Por defecto, el sitio funciona con HTTP, lo que significa que la comunicación entre el usuario y el servidor viaja sin cifrar.
Certbot es LA herramienta que permite obtener e instalar automáticamente un certificado SSL gratuito de Let's Encrypt, habilitando HTTPS en el sitio. Esto cifra toda la comunicación, protege los datos de los usuarios y además es requerido por la mayoría de los navegadores modernos que muestran advertencias de "sitio no seguro" cuando no hay certificado.
(O mejor explicado en palabras de nuestro compañero: es como el certificado de SENASA pero para sitios webs, y lo que estamos haciendo es que nuestro sitio esté "blanqueado", va a tener papeles, y se pueda comunicar con otros sitios que están en iguales condiciones)
Empezamos por instalar Cerbot:
Luego, confirmamos si la configuración de nuestro firewall permite la comunicacion del tipo que necesitamos:
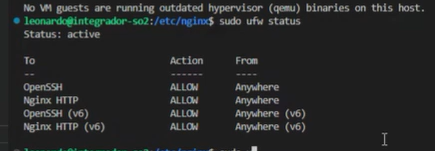
Con esa configuración no podemos avanzar, por lo tanto, tenemos que habilitar los permisos del tipo full para nginx y borrar los dados anteriormente:
root@integrador-so2:~# sudo ufw delete allow 'Nginx HTTP'
confirmamos que todo haya salido bien:
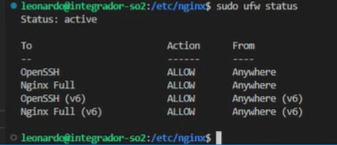
Finalmente, ingresamos el comando que le otorgará el certificado a nuestra página:
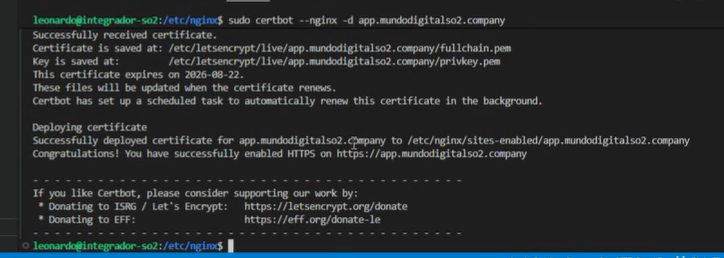
En la imagen podemos verificar que tiene 90 días de valides, venciendo el 22/08/26. Si quisiéramos que se renueve solo podemos ingresar
Verificar que la renovación automática funcione:
Certbot modifica automáticamente el archivo de Nginx para agregar HTTPS y redirigir el tráfico de HTTP a HTTPS, por lo que si vamos a navegador ya podemos ver que está implementado
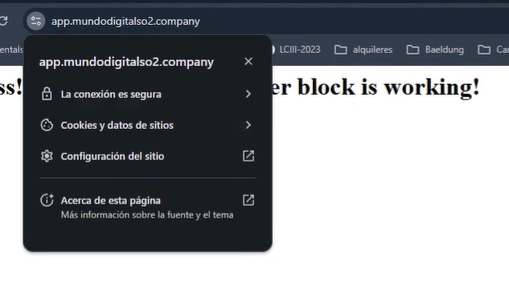
Por último, configuramos el proxy_pass que en vez de servir archivos estáticos, redirige el tráfico hacia la app Node corriendo en el localhost de la misma máquina virtual, y los proxy_set_header que le pasan información sobre el pedido original, como la IP real del cliente, el protocolo usado (HTTP o HTTPS) y datos de la conexión. Esto es necesario porque como Nginx actúa de intermediario, sin estos headers la app Node solo vería la IP de Nginx y no la del usuario real.
proxy_pass http://localhost:3001;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
}
8. Algunas imágenes del Droplet implementado
Tras aproximadamente 6 horas de configuración, correcciones y aprendizaje, logramos tener el servidor corriendo en una máquina virtual remota, con el Swagger del backend de nuestra aplicación disponible y accesible desde cualquier lugar, reemplazando así la dependencia de nuestras máquinas locales.
La presente documentación resume el proceso llevado a cabo, mostrando únicamente el "camino correcto" al que llegamos tras corregir los errores encontrados en el camino, sin detallar cada uno de ellos para no extender innecesariamente el documento.
Un buen ejemplo es la configuración por separado del firewall. Nosotros lo hicimos de manera anticipada a como está reflejado acá, pero luego al seguir la documentación de la instalación de nginx y luego del Cerbot, quedó técnicamente anulada nuestra configuración inicial, por lo que solo mostramos la resultante de proceso.
9. Documentación Completa
Podés descargar el documento Word con la documentación completa del proceso, incluyendo explicaciones adicionales, capturas y decisiones técnicas tomadas durante el desarrollo.
Si el archivo no está disponible aún, consultá a los integrantes del grupo.
Investigación – El Fin de una Era
Windows 10 llegará al final de su soporte en octubre de 2025, lo que significa que Microsoft dejará de ofrecer actualizaciones de seguridad, correcciones de errores y soporte técnico oficial para este sistema operativo. Aunque Windows 10 continuará funcionando después de esa fecha, ya no recibirá protección frente a nuevas amenazas informáticas.
Fecha límite oficial
Octubre de 2025
Microsoft cesa todo soporte, parches y actualizaciones de seguridad para Windows 10.
Principales Riesgos
Exposición a Amenazas
Los equipos quedarán expuestos a virus, malware, ransomware, robo de información y accesos no autorizados, ya que las nuevas vulnerabilidades descubiertas no serán corregidas mediante parches de seguridad. Esto puede comprometer datos personales, archivos y el funcionamiento general del equipo.
Incompatibilidad de Software
Con el tiempo, programas y aplicaciones dejarán de soportar Windows 10, generando errores, fallas de rendimiento y bloqueos funcionales.
Abandono de Drivers
Los fabricantes dejarán de desarrollar drivers y soporte para hardware compatible con este sistema, acelerando su obsolescencia.
Conexión con el Material de SO2
Los sistemas operativos necesitan mantenimiento y actualización constante para garantizar estabilidad y seguridad. Tal como se explica en el material bibliográfico de la materia, el kernel es el encargado de administrar los recursos del hardware y coordinar el funcionamiento del sistema, y también se destaca la importancia de los mecanismos de seguridad y del cifrado de contraseñas para proteger la información de los usuarios.
Por lo tanto, mantener un sistema sin soporte implica operar sobre una base cada vez más vulnerable y menos confiable, razón por la cual se recomienda migrar a una versión moderna o a un sistema operativo que continúe recibiendo soporte activo.
Bibliografía de Referencia
- • Microsoft Learn. (s.f.). Fin del soporte técnico de Windows 10. Microsoft. Recuperado el 24 de mayo de 2026.
- • ISSD. (s.f.). Sistema Operativo II – Clase 1: ¿Qué es GNU/Linux?, El núcleo del sistema (kernel) y Kernel. Material de cátedra.
- • ISSD. (s.f.). Sistema Operativo II – Clase 2: Usuarios y grupos. Material de cátedra.
Eficiencia y Bajos Requisitos en Linux
El ecosistema Linux se destaca globalmente por su excelente optimización y su capacidad para operar eficientemente sobre plataformas con bajos requisitos de hardware. A diferencia de los sistemas operativos comerciales contemporáneos, cuyas crecientes demandas obligan a descartar equipos útiles, Linux permite prolongar la vida útil de computadoras antiguas, garantizando que la mayor parte de los recursos de CPU y memoria se reserven de forma íntegra para las aplicaciones de programación del usuario.
Prioridades de un Entorno de Desarrollo
Para un programador el sistema operativo constituye la base de sus herramientas de trabajo y es por esta razón que hay detalles primordiales que no se pueden desatender, a saber:
Estabilidad y Fiabilidad
Un entorno predictivo que no interrumpa los flujos de trabajo.
Software Actualizado
Acceso directo a las últimas versiones de compiladores y librerías.
Seguridad
Aislamiento nativo de procesos y protección robusta de datos.
Comparativa de Distribuciones y Requisitos
Dentro del gran abanico de opciones disponibles dentro de Linux, Fedora se posiciona como la alternativa idónea frente a sus competidores gracias a su balance tecnológico:
Fedora Workstation
Min: 1 CPU, 1 GB RAM, 10 GB disco
El equilibrio perfecto al ofrecer software moderno e innovador respaldado por una estabilidad semestral rigurosamente testeada.
Ubuntu Desktop
Min: Dual-Core 2 GHz, 4 GB RAM, 25 GB disco
Tiende a la obsolescencia de paquetes en sus versiones estables y ralentiza herramientas debido a su formato de empaquetado.
Arch Linux
Min: x86-64 CPU, 512 MB RAM, 2 GB disco
Ofrece software al día, pero exige un alto mantenimiento manual que pone en riesgo la estabilidad laboral.
Debian GNU/Linux
Min: 1 GHz CPU, 1 GB RAM, 10 GB disco
Extremadamente estable, pero sus herramientas de programación son muy antiguas.
openSUSE Leap
Min: Dual-Core 1.6 GHz, 2 GB RAM, 40 GB disco
Excelente integración empresarial, pero ralentiza la adopción de nuevas tecnologías de desarrollo.
Cualidades Principales de Fedora Workstation
La documentación oficial define a Fedora como una plataforma orientada a satisfacer las necesidades de los desarrolladores, fundamentando su éxito en las siguientes ventajas:
Soporte Multi-Arquitectura
Dispone de imágenes nativas para procesadores x86_64 e Intel/AMD/ARM (aarch64).
Gestión Inteligente de Recursos
Incorpora “zRAM” (compresión de intercambio en memoria para acelerar el multitasking) y control de presión de memoria para prevenir congelamientos del sistema.
Almacenamiento Avanzado (Btrfs)
Implementa un sistema de archivos que comprime automáticamente los datos en disco, protegiendo las unidades y acelerando lecturas.
Estructura Protegida contra Fallos
Sus componentes esenciales de red, arranque e interfaz gráfica (como “NetworkManager” o “grub”) están blindados como “no removibles”, impidiendo que errores accidentales en la terminal rompan el sistema.
Impacto en la Práctica Diaria de un Desarrollador
El beneficio real de Fedora en el día a día de un programador es la tranquilidad operativa: el sistema mitiga los errores de consumo de recursos y protege la integridad de la estación de trabajo frente a fallas imprevistas.
Situémonos en un día cualquiera de un desarrollador y veamos como las características de Fedora juegan un rol decisivo. Si un programador está compilando un proyecto de software de gran escala mientras descarga dependencias de red, y la memoria RAM llega a su límite físico, Fedora no congelará la pantalla. La tecnología “zRAM” comprimirá los datos en la memoria instantáneamente y, de ser necesario, el sistema detendrá de forma aislada el proceso secundario causante del desborde. Esto permite que el entorno de desarrollo principal siga respondiendo, protegiendo las líneas de código recién escritas y evitando pérdidas de tiempo valiosas en reinicios del sistema.
Junto a este ejemplo, sumado a las características y datos ya mencionados podemos concluir que Fedora, es la distribución ideal para un entorno orientado al desarrollo ya que además de estar orientada a esta funcionalidad, posee todo un conjunto de cualidades que la hacen segura, confiable y optima para un entono de desarrollo.
Bibliografía de Referencia
- • Arch Linux Team. (2026). ArchWiki: General recommendations. Recuperado de https://wiki.archlinux.org/
- • Canonical Ltd. (2026). Ubuntu Server and Desktop Documentation. Recuperado de https://help.ubuntu.com/
- • Debian Project. (2026). Debian GNU/Linux Installation Guide. Recuperado de https://www.debian.org/doc/
- • Fedora Project. (2026). Fedora Workstation Documentation. Fedora Docs. Recuperado de https://docs.fedoraproject.org/en-US/workstation-docs/
- • openSUSE Project. (2026). openSUSE Leap Documentation. Recuperado de https://doc.opensuse.org/
Linux, el Motor de la Inteligencia Artificial
4.1 ¿Por qué Linux domina la inteligencia artificial?
Cuando hablamos de inteligencia artificial, muchas veces pensamos en modelos como ChatGPT, reconocimiento de imágenes, autos autónomos o sistemas que aprenden a partir de grandes cantidades de datos. Pero detrás de todo eso hay algo menos visible y muy importante: el sistema operativo donde se entrena y se ejecuta esa IA, y ahí Linux tiene una ventaja enorme.
No es que en Windows no se pueda trabajar con inteligencia artificial, porque sí se puede, pero cuando el trabajo se vuelve más pesado, más profesional o más cercano a servidores reales, Linux suele ser el sistema preferido por desarrolladores, empresas y centros de investigación.
Esto se debe a varias razones técnicas, pero hay dos que ayudan a entenderlo de forma bastante clara: por un lado, Linux permite aprovechar mejor la potencia de las GPU, que son fundamentales para entrenar modelos de IA; y por otro, ofrece un entorno de trabajo muy cómodo para programar, automatizar tareas, usar Docker y desplegar sistemas en servidores.
Linux aprovecha mejor la potencia de las GPU
En inteligencia artificial, la GPU es una pieza clave. Aunque muchas personas la asocian con videojuegos, en realidad una GPU también sirve para hacer miles de cálculos al mismo tiempo, y eso es fundamental para entrenar modelos de IA, porque estos modelos trabajan con enormes cantidades de datos y operaciones matemáticas.
Acá es donde aparece CUDA, una tecnología de NVIDIA que permite usar la GPU para tareas de cálculo intensivo. Dicho de forma más simple, CUDA funciona como un puente entre el programa de inteligencia artificial y la placa de video: le permite al software decirle a la GPU "tomá estos datos y procesalos lo más rápido posible". Linux maneja esto muy bien por su fuerte relación con los drivers de NVIDIA y frameworks como PyTorch o TensorFlow.
Además, en entornos profesionales, muchos servidores no tienen pantalla ni interfaz gráfica y se administran directamente desde la terminal, y es ahí donde Linux destaca. En otras palabras: Linux permite sacarle más jugo al hardware, especialmente cuando hablamos de GPU, y para la inteligencia artificial eso significa entrenamientos más eficientes, mejor uso de la memoria y menos trabas al momento de configurar el entorno. Si la GPU es el motor de un auto de carrera, Linux es el taller donde ese motor se puede ajustar mejor.
Ideal para terminales, Docker y servidores
Linux está orientado a la terminal, una enorme ventaja para automatizar tareas repetitivas: instalar librerías, ejecutar scripts, descargar datasets, entrenar modelos, probar configuraciones, levantar servicios y automatizar procesos de forma rápida y ordenada.
Funciona excelente con Docker para crear contenedores aislados con las dependencias exactas (Python, CUDA, PyTorch). Docker se apoya en características propias del sistema, como el aislamiento de procesos y el control de recursos, lo que permite que el proyecto pueda ejecutarse igual en otra computadora o en un servidor, sin depender tanto de cómo esté configurado el sistema principal. Esto resuelve el clásico problema de "en mi máquina funciona, no sé por qué en la tuya no".
En Linux, estos contenedores corren de forma natural. Windows, en cambio, muchas veces necesita capas extra como WSL2, lo que puede agregar consumo de memoria, problemas de rendimiento o más complejidad al entorno de trabajo.
Por eso Linux reina en centros de datos y la nube, creando entornos estables y automatizables que replican fielmente el destino final de producción del modelo de IA.
Resumiendo
Linux domina la inteligencia artificial porque combina dos ventajas clave: aprovecha al máximo el hardware (especialmente las GPU) y ofrece un entorno inigualable para programar, automatizar y desplegar proyectos. Mientras Windows sirve perfectamente para aprender o realizar proyectos pequeños, cuando hablamos de IA a gran escala con modelos pesados, servidores, Docker y CUDA, Linux es la opción más fuerte, potente y conectada con las herramientas del mundo real.
Fuentes Consultadas
Jupyter Notebook
Origen e historia
Proyecto sin fines de lucro nacido en 2014 a partir de IPython. Su nombre hace referencia a Julia, Python y R, y rinde homenaje a los cuadernos de Galileo.
El Proyecto Jupyter es una organización sin fines de lucro creada para desarrollar software de código abierto para computación interactiva en docenas de lenguajes de programación. Fue creado en 2014 por Fernando Pérez a partir del proyecto IPython.
Para entender bien qué es Jupyter Notebook, hay que remontarse a finales de 2001, cuando Fernando Pérez comenzó a desarrollar IPython. En 2005, Pérez y Robert Kern intentaron construir un sistema de notebook, aunque ese prototipo nunca llegó a ser completamente funcional. En 2007 retomaron el intento, y para octubre de 2010 ya existía un prototipo de notebook web que fue lanzado oficialmente en diciembre de 2011. Finalmente, en 2014, el Proyecto Jupyter nació como una derivación de IPython.
El nombre del proyecto es una referencia a los tres lenguajes de programación principales que soporta: Julia, Python y R. Además, es un homenaje a los cuadernos de Galileo en los que documentó el descubrimiento de las lunas de Júpiter.
¿Qué es y cómo funciona?
Jupyter Notebook es una aplicación web en la que se pueden crear y compartir documentos que contienen código en vivo, ecuaciones, visualizaciones y texto. Es una de las herramientas más utilizadas en ciencia de datos porque permite combinar el análisis, su descripción y sus resultados en un mismo lugar, ejecutándolo todo en tiempo real.
Su unidad básica es la celda, y hay dos tipos principales. Las celdas de código permiten escribir y ejecutar, mostrando el resultado justo debajo. Las celdas de Markdown permiten agregar texto explicativo, títulos y ecuaciones matemáticas.
Técnicamente es una aplicación cliente‑servidor. Sus dos componentes principales son el kernel, que es el programa que ejecuta el código del usuario, y el dashboard, que muestra los documentos disponibles y permite gestionar los kernels en ejecución.
El archivo resultante tiene extensión
.ipynb
y es un documento JSON que puede convertirse a múltiples
formatos estándar como HTML, PDF, LaTeX, Markdown o Python
a través de la interfaz web.
¿Para qué se usa?
Jupyter Notebook no es solo un entorno de desarrollo, sino
un espacio de trabajo, aprendizaje y colaboración. Permite
visualizar gráficos directamente, guardar todo en un
archivo
.ipynb
que se puede reabrir o compartir, y trabajar con datos
analizándolos y documentando todo de forma clara.
Es especialmente popular en investigación y enseñanza porque permite documentar todo el proceso junto al código. Esto lo convierte en una herramienta ideal para construir portfolios de ciencia de datos, hacer exploraciones rápidas, participar en desafíos de datos, reportar investigaciones o construir flujos de procesamiento de datos.
Es además compatible con herramientas como TensorFlow, PyTorch y Scikit‑learn, las otras opciones de esta consigna, lo que lo convierte en el entorno de trabajo más común para quienes las utilizan.
Jupyter vs Script Tradicional
La diferencia principal con escribir un script de Python convencional es la interactividad. A diferencia de un script tradicional donde hay que reescribir y volver a correr todo el programa cada vez que se hace un cambio, en Jupyter se puede modificar una sola celda y ejecutarla de manera aislada, viendo el resultado al instante.
Además, las buenas prácticas recomiendan importar las librerías necesarias en la primera celda del notebook, mantener las celdas simples y no muy extensas, y agregar texto explicativo entre el código para que el notebook sea comprensible para otros. Esto agiliza enormemente el proceso de exploración y análisis.
Nota: Detractores de la Herramienta
Me gustaría aclarar que más allá de las virtudes que principalmente cité, hay muchos detractores de esta herramienta de IA. Sobre todo, los artículos que he leído en towardsdatascience.com citan grandes limitaciones para implementar las investigaciones en el mercado, e incentivan el uso de herramientas de Python.
Me pareció pertinente hacer la aclaración porque en este momento, la IA misma pasa por un proceso de amor/odio en todos los rubros, y este no es la excepción.
Conclusiones de Caso de Estudio
Reflexiones sobre la viabilidad académica y despliegues técnicos sustentables y soberanos.
"En este video, el grupo comparte sus conclusiones y reflexiones sobre el proceso de configuración de un servidor remoto en Digital Ocean, que incluyó la creación de un Droplet con Ubuntu, la gestión de usuarios y permisos, la implementación de Nginx, PM2 y Certbot, entre otras herramientas. Más que un tutorial técnico, es una charla donde contamos cómo vivimos la experiencia, qué nos resultó difícil, qué aprendimos y qué nos llevamos del trabajo. Para una mejor documentación, ponemos de fondo el proceso (aunque muy acelerado) para dejar testimonio de lo comentado."
— ¡Esperamos sea de su agrado!